近几年,图像生成领域取得了巨大的进步,尤其是文本到图像生成方面取得了重大突破:只要我们用文本描述自己的想法,AI 就能生成新奇又逼真的图像。
但其实我们可以更进一步 —— 将头脑中的想法转化为文本这一步可以省去,直接通过脑活动(如 EEG(脑电图)记录)来控制图像的生成创作。
这种「思维到图像」的生成方式有着广阔的应用前景。例如,它能极大提高艺术创作的效率,并帮助人们捕捉稍纵即逝的灵感;它也有可能将人们夜晚的梦境进行可视化;它甚至可能用于心理治疗,帮助自闭症儿童和语言障碍患者。
最近,来自清华大学深圳国际研究生院、腾讯 AI Lab 和鹏城实验室的研究者们联合发表了一篇「思维到图像」的研究论文,利用预训练的文本到图像模型(比如 Stable Diffusion)强大的生成能力,直接从脑电图信号生成了高质量的图像。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
论文地址:https://arxiv.org/pdf/2306.16934.pdf
项目地址:https://github.com/bbaaii/DreamDiffusion
 Android 应用框架原理与程序设计36技pdf繁体版
Android 应用框架原理与程序设计36技pdf繁体版
Android应用框架原理与程序设计36技 pdf繁体版,书籍内容适用于Android 1.0,有些朋友可能对Android还不太熟悉吧?不知您是否听说过Google 在HTC定制的高端手机呢?其操作系统是基于Android的,如果还是不太清楚的话,可以Google一下“HTC g2”手机,可以大致了解一下手机操作系统的界面及架构特点。不管怎么说,Android手机编程目前还是主要面向高端,在将来可能会普及,因此Android编程还是很有必要掌握的。
 0
查看详情
0
查看详情


近期一些相关研究(例如 MinD-Vis)尝试基于 fMRI(功能性磁共振成像信号)来重建视觉信息。他们已经证明了利用脑活动重建高质量结果的可行性。然而,这些方法与理想中使用脑信号进行快捷、高效的创作还差得太远,这主要有两点原因:
首先,fMRI 设备不便携,并且需要专业人员操作,因此捕捉 fMRI 信号很困难;
其次,fMRI 数据采集的成本较高,这在实际的艺术创作中会很大程度地阻碍该方法的使用。
相比之下,EEG 是一种无创、低成本的脑电活动记录方法,并且现在市面上已经有获得 EEG 信号的便携商用产品。
但实现「思维到图像」的生成还面临两个主要挑战:
1)EEG 信号通过非侵入式的方法来捕捉,因此它本质上是有噪声的。此外,EEG 数据有限,个体差异不容忽视。那么,如何从如此多的约束条件下的脑电信号中获得有效且稳健的语义表征呢?
2)由于使用了 CLIP 并在大量文本 - 图像对上进行训练,Stable Diffusion 中的文本和图像空间对齐良好。然而,EEG 信号具有其自身的特点,其空间与文本和图像大不相同。如何在有限且带有噪声的 EEG - 图像对上对齐 EEG、文本和图像空间?
为了解决第一个挑战,该研究提出,使用大量的 EEG 数据来训练 EEG 表征,而不是仅用罕见的 EEG 图像对。该研究采用掩码信号建模的方法,根据上下文线索预测缺失的 token。
不同于将输入视为二维图像并屏蔽空间信息的 MAE 和 MinD-Vis,该研究考虑了 EEG 信号的时间特性,并深入挖掘人类大脑时序变化背后的语义。该研究随机屏蔽了一部分 token,然后在时间域内重建这些被屏蔽的 token。通过这种方式,预训练的编码器能够对不同个体和不同脑活动的 EEG 数据进行深入理解。
对于第二个挑战,先前的解决方法通常直接对 Stable Diffusion 模型进行微调,使用少量噪声数据对进行训练。然而,仅通过最终的图像重构损失对 SD 进行端到端微调,很难学习到脑信号(例如 EEG 和 fMRI)与文本空间之间的准确对齐。因此,研究团队提出采用额外的 CLIP 监督,帮助实现 EEG、文本和图像空间的对齐。
具体而言,SD 本身使用 CLIP 的文本编码器来生成文本嵌入,这与之前阶段的掩码预训练 EEG 嵌入非常不同。利用 CLIP 的图像编码器提取丰富的图像嵌入,这些嵌入与 CLIP 的文本嵌入很好地对齐。然后,这些 CLIP 图像嵌入被用于进一步优化 EEG 嵌入表征。因此,经过改进的 EEG 特征嵌入可以与 CLIP 的图像和文本嵌入很好地对齐,并更适合于 SD 图像生成,从而提高生成图像的质量。
基于以上两个精心设计的方案,该研究提出了新方法 DreamDiffusion。DreamDiffusion 能够从脑电图(EEG)信号中生成高质量且逼真的图像。
 图片
图片
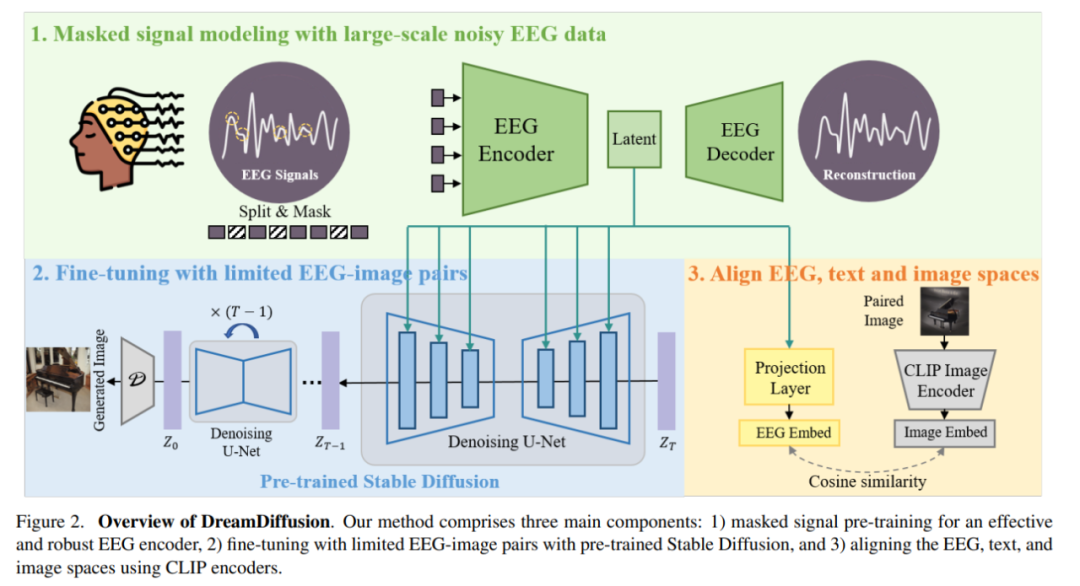
具体来说,DreamDiffusion 主要由三个部分组成:
1)掩码信号预训练,以实现有效和稳健的 EEG 编码器;
2)使用预训练的 Stable Diffusion 和有限的 EEG 图像对进行微调;
3)使用 CLIP 编码器,对齐 EEG、文本和图像空间。
首先,研究人员利用带有大量噪声的 EEG 数据,采用掩码信号建模,训练 EEG 编码器,提取上下文知识。然后,得到的 EEG 编码器通过交叉注意力机制被用来为 Stable Diffusion 提供条件特征。
 图片
图片
为了增强 EEG 特征与 Stable Diffusion 的兼容性,研究人员进一步通过在微调过程中减少 EEG 嵌入与 CLIP 图像嵌入之间的距离,进一步对齐了 EEG、文本和图像的嵌入空间。
与 Brain2Image 对比
研究人员将本文方法与 Brain2Image 进行比较。Brain2Image 采用传统的生成模型,即变分自编码器(VAE)和生成对抗网络(GAN),用于实现从 EEG 到图像的转换。然而,Brain2Image 仅提供了少数类别的结果,并没有提供参考实现。
鉴于此,该研究对 Brain2Image 论文中展示的几个类别(即飞机、南瓜灯和熊猫)进行了定性比较。为确保比较公平,研究人员采用了与 Brain2Image 论文中所述相同的评估策略,并在下图 5 中展示了不同方法生成的结果。
下图第一行展示了 Brain2Image 生成的结果,最后一行是研究人员提出的方法 DreamDiffusion 生成的。可以看到 DreamDiffusion 生成的图像质量明显高于 Brain2Image 生成的图像,这也验证了本文方法的有效性。
 图片
图片
消融实验
预训练的作用:为了证明大规模 EEG 数据预训练的有效性,该研究使用未经训练的编码器来训练多个模型进行验证。其中一个模型与完整模型相同,而另一个模型只有两层的 EEG 编码层,以避免数据过拟合。在训练过程中,这两个模型分别进行了有 / 无 CLIP 监督的训练,结果如表 1 中 Model 列的 1 到 4 所示。可以看到,没有经过预训练的模型准确性有所降低。
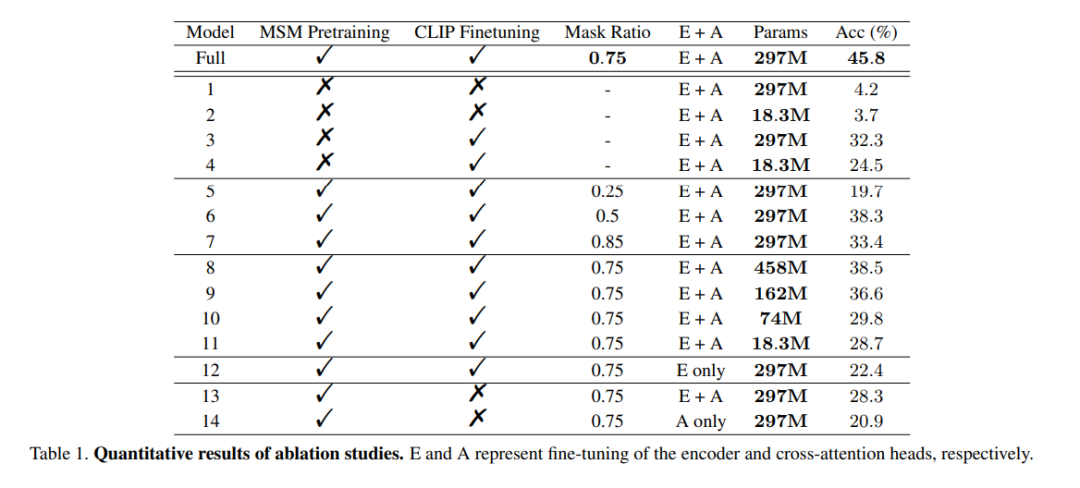
mask ratio:本文还研究了用 EEG 数据确定 MSM 预训练的最佳掩码比。如表 1 中的 Model 列的 5 到 7 所示,过高或过低的掩码比会对模型性能都会产生不利影响。当掩码比为 0.75 达到最高的整体准确率。这一发现至关重要,因为这表明,与通常使用低掩码比的自然语言处理不同,在对 EEG 进行 MSM 时,高掩码比是一个较好的选择。
CLIP 对齐:该方法的关键之一是通过 CLIP 编码器将 EEG 表征与图像对齐。该研究进行实验验证了这种方法的有效性,结果如表 1 所示。可以观察到,当没有使用 CLIP 监督时,模型的性能明显下降。实际上,如图 6 右下角所示,即使在没有预训练的情况下,使用 CLIP 对齐 EEG 特征仍然可以得到合理的结果,这凸显了 CLIP 监督在该方法中的重要性。
 图片
图片
以上就是你大脑中的画面,现在可以高清还原了的详细内容,更多请关注其它相关文章!
# ai
# 浙江电商网站推广多少钱
# seo里填写什么意思
# 刘学超seo
# 淘宝外部网站的推广特点
# 乌苏营销推广运营思路
# 大气网站建设哪家好
# 并在
# 重构
# 不太
# 很好
# 万元
# 高质量
# 所示
# 程序设计
# 掩码
# 脑中
# stable diffusion
# 创意
# 网站建设优化推广采购
# 昆山建设网站的
# 360网站优化论坛
# 新媒体营销推广的特点
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
走进首家“元宇宙”未来工厂,卡奥斯探知工业之旅出发!
陈根教授:离人形机器人时代还有10年吗?
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
梦想实现!硬核科幻大片VR智能头盔即将问世
成都大运会闭幕式引入人形机器人展示表演
AI和ML推动联网设备的增长
世界人工智能大会中西部县域数字就业中心组团亮相
上天下海登极,青岛与昇腾AI握手一起探索星辰大海
你们的开机第一屏画面要变了!安卓机器人首次3D化
如何成功实施人工智能?
传字节内测对话式 AI 产品,代号「Grace」;马斯克嘲讽苹果 头显;比亚迪 F 品牌定名「方程豹」
食品分销跨国企业Sysco CIDO:我们的增长秘诀是以IT为中心
靠游戏更靠AI 英伟达成唯一首季度两位数增长的公司
人工智能即将进入Windows:企业准备好安全策略设置了吗?
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
大型无人机FH-98国内首次夜航转场成功
微软必应聊天现已在Chrome和Safari浏览器上可用,但仍有许多限制存在
北京市通用人工智能产业创新伙伴计划名单公布,京东科技入选“算力伙伴”
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
读创正式上线“读创AI聊”功能
探展WAIC | 第四范式“式说”聚焦toB大模型,布局生成式AI重构企业软件
阿里云全面支持Llama2训练部署,助力企业快速构建自有大型模型
利好来了,AI再起一波?
日媒关注中国推进鸟类识别 AI 普及,除监测保护外还可预防传染性疾病
微软 Copilot 团队主管呼吁用户与 AI 交流时应使用恰当的礼貌用语
视觉中国宣布推出AI灵感绘图、画面扩展功能
人工智能进入绿植界,智能庭院市场初具规模
应用生成式人工智能技术改善农业产业
阿里达摩院向公众免费开放100项AI专利许可
了解 AGI:智能的未来?
社区里,孩子们体验“机器人竞技”
鸿蒙智能座舱的AI大模型革新,引领智能座舱领域的变革吗?
基于预训练模型的金融事件分析及应用
1.6亿美元收购Singularity AI,昆仑万维布局通用人工智能
扎克·施奈德新片《月球叛军》曝剧照 机器人首度现身
MiracleVision视觉大模型功能介绍
华为余承东表示:鸿蒙可能拥有强大的人工智能大模型能力
「电子果蝇」惊动马斯克!背后是13万神经元全脑图谱,可在电脑上运行
AI 模型 Stable Diffusion 升级:正常生成五指、图像更逼真
机器人加速!稀土永磁也被带火,持续性如何?
生成式AI爆发,亚马逊云科技持续专注创新,助力企业数字化转型
中国气象局预测:到 2030 年,中国人工智能气象应用将达到国际领先水平
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
高通发布长期产品计划,为工业和企业物联网产品提供全新组合方案
令人惊叹!AI模型能够以iPhone照片为基础创作诗歌
清华朱军团队新作:使用4位整数训练Transformer,比FP16快2.2倍,提速35.1%,加速AGI到来!
湖北科技职业学院举行工业机器人及智能制造技术专精特新产业学院建设启动仪式
猿辅导推出Motiff,整合三大AI功能,助力UI设计生产力革新
深企派遣无人机救援队赴京津冀开展防汛救灾任务
2023-07-06

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
