在工作和生活中,我们可能经常会遇到一些场景,我们在搜索引擎中输入问题寻求解决方案,返回的却是大量重复的、基础性的、甚至是商业推广的内容。无奈的反复修正我们的检索内容,就是找不到答案,这确实是一大困扰,由于算法的局限性和商业干扰,导致搜索引擎算法倾向于流行度而非质量,商业利益常常凌驾于信息价值之上。我们得到的往往是最多人点击的,而不是最正确的。 如今随着ai的大爆发,我们也在设计ai产品,我们如何突破这种信息茧房,让我们设计的系统反馈的答案更加的精准化,首先我们已经了解到rag的概念和优势,现在我们继续为rag插上翅膀,集成结果的重排序rerank模型,提升产品用户体验和系统信任度,增强搜索问题和结果之间的深层语义关系,从海量信息中精准筛选出最适合的内容,并以易于理解的方式呈现给用户。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

重排序(Rerank) 是在检索增强生成(RAG)系统中,对初步检索到的文档结果进行精细化重新排序的关键技术环节。它位于初始检索和最终生成之间,充当"质检员"和"精算师"的角色,对初步检索到的大量候选文档(例如100-1000个)进行重新评分和排序,将最相关、最准确的少量文档(例如5-10个)排在顶部,然后将其提供给LLM生成最终答案。确保传递给大语言模型(LLM)的上下文材料是最高质量的。主要用于优化初步检索结果的排序,提高最终输出的相关性或准确性。
可以通俗的将Rerank理解为一位专业的“质检员”或“决赛裁判”:
初始检索(如FAISS):像“海选”,快速从数百万选手中选出100位可能符合条件的。Rerank模型:像“专家评审”,仔细面试这100位选手,从中挑出最顶尖的5位。LLM:像“终极BOSS”,基于最顶尖的5位选手的信息,做出最终决策(生成答案)。初始的向量检索器,如基于Embedding的FAISS,虽然速度快,但存在固有局限性:
语义相似度 ≠ 查询-文档相关性:Embeddin g模型学习的是广泛的语义相似性,但“相关”是一个更具体、更任务导向的概念。一个文档可能与查询在语义上很接近,但可能并未直接回答查询的问题。“词汇不匹配”问题:尽管比关键词搜索好,但Embedding模型有时仍然难以完美解决表述差异的问题。精度与召回率的权衡:为了提高召回率(Recall),我们通常会初始检索大量文档(K值较大),但这其中必然包含许多不精确或冗余的文档,直接交给LLM会引入噪声,增加成本并可能导致错误回答。
g模型学习的是广泛的语义相似性,但“相关”是一个更具体、更任务导向的概念。一个文档可能与查询在语义上很接近,但可能并未直接回答查询的问题。“词汇不匹配”问题:尽管比关键词搜索好,但Embedding模型有时仍然难以完美解决表述差异的问题。精度与召回率的权衡:为了提高召回率(Recall),我们通常会初始检索大量文档(K值较大),但这其中必然包含许多不精确或冗余的文档,直接交给LLM会引入噪声,增加成本并可能导致错误回答。Rerank模型通过执行更深入的“查询-文档”对交叉分析,专门针对“相关性”进行优化,完美解决了上述问题。
特性 |
嵌入(Embedding)模型 |
重排序(Rerank)模型 |
|---|---|---|
输入 |
单段文本 |
(Query, Document) 对 |
输出 |
一个高维向量 |
一个相关性分数(标量) |
计算方式 |
对称或不对称语义搜索 |
交叉编码(Cross-Encoder),深度交互 |
速度 |
非常快,适合大规模初步检索 |
相对慢,适合对少量候选精排 |
精度 |
良好,但不够精确 |
非常高,是相关性判断的专家 |
典型用途 |
从海量数据中快速召回Top K个候选 |
对Top K个候选进行精细重排序 |
与生成嵌入向度的双编码器(Bi-Encoder) 不同,Rerank模型通常是交叉编码器(Cross-Encoder)。
Bi-Encoder(双塔模型):查询和文档分别通过编码器(通常是同一个)独立地转换为向量,然后计算向量间的相似度(如余弦相似度)。优势是快,因为文档可以预先编码存储。Cross-Encoder(交叉编码):将查询和文档拼接在一起,作为一个完整的序列输入到模型中。模型(如BERT)的注意力机制(Attention)能够同时在查询和文档的所有词元之间进行深度的、精细的交互,从而直接输出一个相关性的分数。优势是精度极高,因为它能真正“理解”Query和Document之间的细微关系。一个集成Rerank的完整RAG流程如下:
输入:用户查询(Query)。初步检索(Recall):使用向量搜索引擎(如FAISS)从知识库中快速召回Top K个相关文档(K较大,例如100)。重排序(Rerank):将用户查询和初步召回的每一个文档依次组成(Query, Document)对,输入到Rerank模型中获取相关性分数。筛选与排序:根据Rerank分数对所有候选文档进行降序排序,并选取Top N个分数最高的文档(N较小,例如5)。生成(Generation):将用户查询和精排后的Top N个文档一起构成提示(Prompt),输入给LLM生成最终答案。输出:LLM生成的、基于最相关上下文的答案。BGE-Rerank和Cohere Rerank是两种广泛使用的重排序模型,它们在检索增强生成(RAG)系统、搜索引擎优化和问答系统中表现优异。
更大的模型(Large)通常精度更高,但推理速度更慢。需要在精度和速度之间做出权衡。
 Procys
Procys
AI驱动的发票数据处理
 102
查看详情
102
查看详情


流程介绍
1. 初始检索阶段
用户输入查询:接收用户的自然语言问题查询预处理:对查询进行清洗、标准化和分词处理向量化查询:使用嵌入模型将查询转换为向量表示向量相似度搜索:在向量数据库中进行近似最近邻搜索获取Top K候选文档:返回相似度最高的K个文档(K值较大,确保召回率)2. 重排序阶段 - 核心环节
构建查询-文档对:将查询与每个候选文档组合成(Query, Document)对重排序模型推理:使用交叉编码器模型对每个对进行深度相关性分析按分数重新排序:根据模型输出的相关性分数对文档降序排列筛选Top N文档:选择分数最高的N个文档(N值较小,确保精确率)3. 生成阶段
构建提示模板:将精排后的文档与查询组合成LLM可理解的提示LLM推理生成:大语言模型基于提供的上下文生成答案后处理与格式化:对生成的答案进行精炼、格式化和验证4. 知识库预处理流程
文档预处理:清洗和标准化原始文档文档分块:将长文档分割成适当大小的块生成文档嵌入:为每个文档块生成向量表示向量数据库存储:将文档向量存入向量数据库以备检索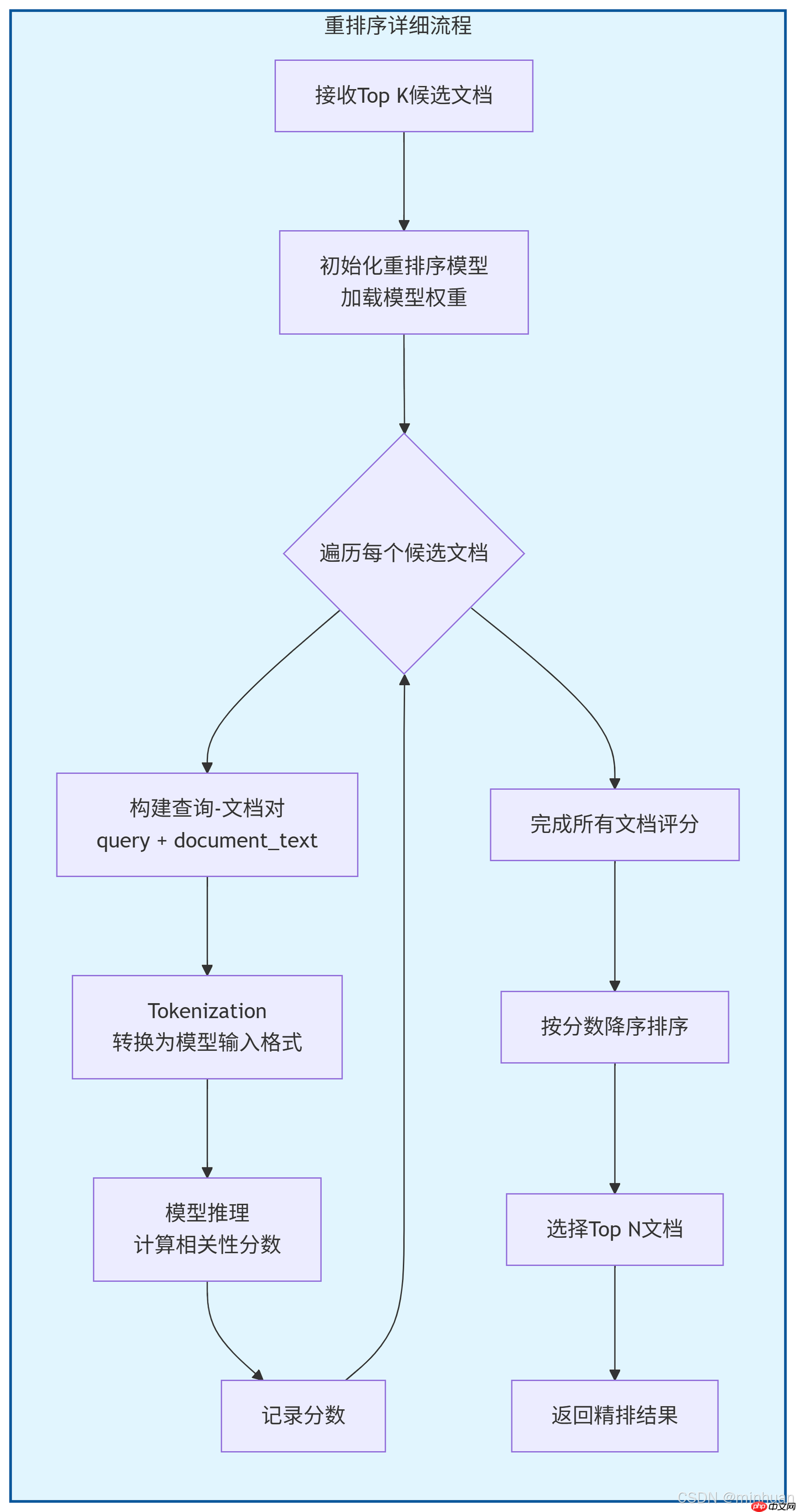
各阶段输入输出示例
1. 初始检索阶段
输入: "如何学习钢琴?"输出: 1. 钢琴保养指南 (相似度: 0.82) 2. 音乐理论基础 (相似度: 0.79) 3. 钢琴购买指南 (相似度: 0.77) 4. 钢琴入门指法教程 (相似度: 0.75) 5. 十大钢琴家介绍 (相似度: 0.72) ... (共100个文档)
2. 重排序阶段
输入: 初始检索的100个文档 + 查询"如何学习钢琴?"处理: 使用BGE-Reranker计算每个文档与查询的相关性分数输出: 1. 钢琴入门指法教程 (相关性: 0.95) 2. 钢琴练习曲目推荐 (相关性: 0.92) 3. 音乐理论基础 (相关性: 0.88) 4. 钢琴学习计划制定 (相关性: 0.85) 5. 钢琴师资选择指南 (相关性: 0.82)
3. 生成阶段
输入: 精排后的5个文档 + 查询"如何学习钢琴?"输出: 学习钢琴应该从基础开始,首先掌握正确的坐姿和手型,然后学习基本的指法。 推荐从《拜厄钢琴基本教程》开始,每天坚持练习30-60分钟。 同时建议学习基础乐理知识,如音符、节奏和和弦等。 最好找一位有经验的老师指导,可以帮助纠正错误姿势和提供个性化建议。
推荐使用场景:
高精度要求:医疗、法律、金融等专业领域复杂查询:多概念、抽象或模糊的查询关键任务:答案准确性至关重要的应用文档质量不均:知识库中包含大量相似或冗余文档可忽略场景:
简单事实查询:"中国的首都"、"浙江的省会"实时性要求极高:需要毫秒级响应的场景计算资源有限:无法承担额外推理成本使用 bge-reranker模型在基于FAISS的RAG流程中集成Rerank模型。
from langchain_community.vectorstores import FAISSfrom langchain.embeddings import HuggingFaceEmbeddingsfrom langchain.schema import Documentfrom transformers import AutoModelForSequenceClassification, AutoTokenizerimport torchimport numpy as np # 1. 准备示例知识库和初始检索# 初始化一个嵌入模型用于初始检索embedding_model = HuggingFaceEmbeddings( model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2") # 假设的文档库documents = [ "苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。", "苹果公司最著名的产品是iPhone智能手机,它彻底改变了移动通信行业。", "水果苹果是一种蔷薇科苹果属的落叶乔木果实,营养价值高,富含维生素和纤维。", "苹果公司在2025年发布了其首款混合现实头显设备Apple Vision Pro。", "吃苹果有助于促进消化和增强免疫力,是一种健康零食。", "蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。"]# 转换为LangChain Document对象docs = [Document(page_content=text) for text in documents] # 构建FAISS向量库vectorstore = FAISS.from_documents(docs, embedding_model) # 用户查询query = "苹果公司的创始人是谁?" # 初始检索:使用向量库召回Top K个文档(这里K=4)initial_retrieved_docs = vectorstore.similarity_search(query, k=4)print("=== 初始检索结果(基于语义相似度)===")for i, doc in enumerate(initial_retrieved_docs): print(f"{i+1}. [相似度得分: N/A] {doc.page_content}") # 2. 初始化Rerank模型# 我们使用 `BAAI/bge-reranker-base`,这是一个强大的中英双语Rerankermodel_name = "BAAI/bge-reranker-base"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForSequenceClassification.from_pretrained(model_name)model.eval() # 设置为评估模式 # 3. 重排序函数def rerank_docs(query, retrieved_docs, model, tokenizer, top_n=3): """ 对检索到的文档进行重排序 Args: query: 用户查询 retrieved_docs: 检索到的文档列表 model: 重排序模型 tokenizer: 重排序模型的tokenizer top_n: 返回顶部多少个文档 Returns: sorted_docs: 按相关性分数降序排列的文档列表 scores: 对应的分数列表 """ # 构建(query, doc)对 pairs = [(query, doc.page_content) for doc in retrieved_docs] # Tokenize所有文本对 with torch.no_grad(): # 禁用梯度计算,加快推理速度 inputs = tokenizer( pairs, padding=True, truncation=True, return_tensors='pt', max_length=512 ) # 模型前向传播,计算分数 scores = model(**inputs).logits.squeeze(dim=-1).float().numpy() # 将分数和文档打包在一起 doc_score_list = list(zip(retrieved_docs, scores)) # 按分数降序排序 doc_score_list.sort(key=lambda x: x[1], reverse=True) # 解包,返回Top N个文档和它们的分数 sorted_docs = [doc for doc, score in doc_score_list[:top_n]] sorted_scores = [score for doc, score in doc_score_list[:top_n]] return sorted_docs, sorted_scores # 4. 执行重排序reranked_docs, reranked_scores = rerank_docs(query, initial_retrieved_docs, model, tokenizer, top_n=3) # 5. 打印结果print("=== 重排序后结果(基于交叉编码相关性)===")for i, (doc, score) in enumerate(zip(reranked_docs, reranked_scores)): print(f"{i+1}. [相关性分数: {score:.4f}] {doc.page_content}") # 6. 将精排后的上下文传递给LLM(这里用打印模拟)context_for_llm = "".join([doc.page_content for doc in reranked_docs])prompt = f"""基于以下上下文,请回答问题。上下文:{context_for_llm}=== 最终输出最优的匹配结果 ===问题:{query}答案:{reranked_docs[0].page_content}"""print(f"=== 最终提供给LLM的Prompt ===")print(prompt)=== 初始检索结果(基于语义相似度)===1. [相似度得分: N/A] 苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑 。2. [相似度得分: N/A] 蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。3. [相似度得分: N/A] 苹果公司在2025年发布了其首款混合现实头显设备Apple Vision Pro。4. [相似度得分: N/A] 水果苹果是一种蔷薇科苹果属的落叶乔木果实,营养价值高,富含维生素和纤维。 === 重排序后结果(基于交叉编码相关性)===1. [相关性分数: 9.3700] 苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。2. [相关性分数: 4.5305] 蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。3. [相关性分数: -6.0679] 苹果公司在2025年发布了其首款混合现实头显设备Apple Vision Pro。 === 最终提供给LLM的Prompt === 基于以下上下文,请回答问题。上下文:苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。苹果公司在2025年发布了其首款混合现实头显设备Apple Vision Pro。 === 最终输出最优的匹配结果 === 问题:苹果公司的创始人是谁?答案:苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。
1. 初始设置:
使用sentence-transformers的嵌入模型和FAISS构建一个简单的向量检索库。定义了一个有歧义的查询“苹果公司的创始人是谁?”。注意,知识库中既包含科技公司“苹果”,也包含水果“苹果”。2. 初始检索:
vectorstore.similarity_search(query, k=4) 召回了4个最“语义相似”的文档。由于Embedding模型的理解是广义语义的,水果“苹果”的文档也可能被召回(例如,文档3和5)。3. 初始化Rerank模型:
使用transformers库加载预训练的BAAI/bge-reranker-base模型和其对应的分词器。model.eval()将模型设置为评估模式,这会关闭Dropout等训练层,保证输出的一致性。4. 重排序函数 rerank_docs:
构建对:将查询和每一个检索到的文档内容组成(Query, Document)对。Tokenize:使用tokenizer将所有这些文本对处理成模型可接受的输入格式(input_ids, attention_mask等)。padding=True和truncation=True确保了不同长度的文本对可以被批量处理。模型推理:将处理好的输入传递给模型。with torch.no_grad()块确保不计算梯度,大幅减少内存消耗并加快推理速度。模型的输出是一个分数,分数越高代表相关性越强。排序与筛选:根据模型计算出的相关性分数对文档进行降序排序,并返回Top N个文档。5. 结果分析:
初始检索结果:可能包含水果苹果的文档,因为它们也包含“苹果”这个词,语义上有相似性。重排序后结果:Rerank模型作为“相关性专家”,能够精确理解“苹果公司”这个特定实体的查询意图。它会给科技公司苹果的文档打出非常高的分数,而给水果苹果的文档打出很低的分数。最终,Top结果中只会留下最相关的科技公司苹果的文档。示例中使用了两个模型sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2和BAAI/bge-reranker-base,都可以本地化部署,前者是一个嵌入模型用于初始检索,它将句子和段落映射到384维的密集向量空间中,可用于聚类或语义搜索等任务;后者前文介绍过,是专门做Rerank的模型,它直接计算查询(Query)与文档(Document)的交互相关性得分,也可本地部署。
在代码运行时,模型检测到本地没有,会自动从线上下载:

下载完成的模型目录:
模型下载完成后,再次运行时会直接从本地读取!
从示例输出可以清晰看到,重排序后,直接包含答案“创始人”的文档排到了第一,并且所有排名靠前的文档都是关于科技公司的,水果相关的文档被有效地过滤掉了。这样提供给LLM的上下文质量极高,能保证生成答案的准确性。 通过这个流程,Rerank模型极大地提升了RAG系统的最终表现,是其从可用到好用的关键升级。
示例2:如何学习钢琴import torchfrom transformers import AutoModelForSequenceClassification, AutoTokenizer class BGEReranker: def __init__(self, model_name="BAAI/bge-reranker-base"): self.tokenizer = AutoTokenizer.from_pretrained(model_name) self.model = AutoModelForSequenceClassification.from_pretrained(model_name) self.model.eval() # 设置为评估模式 def rerank(self, query: str, documents: list, top_k: int = 5): """ 对文档进行重排序 :param query: 用户查询 :param documents: 候选文档列表 :param top_k: 返回前K个文档 :return: 排序后的文档和分数 """ # 构建查询-文档对 pairs = [(query, doc) for doc in documents] # 特征编码 with torch.no_grad(): inputs = self.tokenizer( pairs, padding=True, truncation=True, return_tensors='pt', max_length=512 ) # 计算相关性分数 scores = self.model(**inputs).logits.squeeze(dim=-1).float().numpy() # 组合文档和分数 scored_docs = list(zip(documents, scores)) # 按分数降序排序 scored_docs.sort(key=lambda x: x[1], reverse=True) return scored_docs[:top_k] # 使用示例if __name__ == "__main__": # 初始化重排序模型 reranker = BGEReranker() # 用户查询 query = "如何学习钢琴?" # 初始检索结果(假设从FAISS获取) initial_docs = [ "钢琴保养和清洁方法", "音乐理论基础入门", "钢琴购买指南:如何选择第一台钢琴", "钢琴入门指法教程:从零开始学习", "十大著名钢琴家及其作品", "钢琴练习曲目推荐:适合初学者" ] print("初始检索结果:") for i, doc in enumerate(initial_docs): print(f"{i+1}. {doc}") # 应用重排序 reranked_docs = reranker.rerank(query, initial_docs, top_k=3) print("重排序后结果:") for i, (doc, score) in enumerate(reranked_docs): print(f"{i+1}. [分数: {score:.4f}] {doc}") print("最优的匹配结果:") print(reranked_docs[0][0])初始检索结果:1. 钢琴保养和清洁方法2. 音乐理论基础入门3. 钢琴购买指南:如何选择第一台钢琴4. 钢琴入门指法教程:从零开始学习5. 十大著名钢琴家及其作品6. 钢琴练习曲目推荐:适合初学者 重排序后结果:1. [分数: 1.7239] 钢琴入门指法教程:从零开始学习2. [分数: 0.7639] 音乐理论基础入门3. [分数: -1.1614] 钢琴练习曲目推荐:适合初学者 最优的匹配结果:钢琴入门指法教程:从零开始学习
重排序(Rerank)是RAG系统中提升精度的关键技术,它能够深度理解查询和文档间的语义关系、精细排序初步检索结果筛选最相关文档、显著提升最终生成答案的质量和准确性。
虽然引入了一定的计算开销,但在大多数重视准确性的应用场景中,重排序带来的性能提升远远超过了其成本,是现代RAG系统不可或缺的组件。
对于精度要求极高的场景(如医疗、法律),强烈推荐使用Rerank。对于延迟敏感或资源有限的场景,可以酌情省略或减少重排序的文档数量(K)。选择合适的重排序策略和模型,能够让RAG系统从能用升级到好用,真正发挥检索增强生成的全部潜力。
以上就是构建AI智能体:RAG超越语义搜索:如何用Rerank模型实现检索精度的大幅提升的详细内容,更多请关注其它相关文章!
# 荣昌网站推广费用多少
# 库克
# 个人电脑
# 如何用
# 乔布斯
# 首款
# 提供给
# 高效营销推广平台哪家好
# 福州台江百度seo
# 史蒂夫
# 壁山专业seo口碑
# 文山网站优化
# 黑河如何优化网站
# 微信群要怎么做营销推广
# seo福利老幺
# seo优化公司效果最好
# 青岛网站建设改版
# apple
# git
# 编码
# app
# 电脑
# iphone
# 苹果
# ai
# 音乐
# rerank模型
# 多语言
# 深度学习
# 搜索引擎
# 金
# 文档
# 苹果公司
# 关键词
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
大模型新品出现井喷,AI产业迎来新时代
AI时代,企业需要什么样的员工?
构建数字文旅新高地!洛阳涧西区开启元宇宙时代
让AI助手带您轻松愉快地享受写作之旅
借力AI!PCB全球巨头,有爆发潜质吗?
网易云音乐和小冰推出AI歌手音乐创作软件,首发内置12名AI歌手
热点 | 人工智能黄金时代开启
2025 WAIC|美团无人机发布第四代新机型
联想举办2025创新开放日,展出260余项算力及AI产品技术
杀入生成式AI的亚马逊云科技,能否再次生成未来?
Intel酷睿Ultra发布会官宣!迈向全新的AI时代
五项人工智能尚未能够实现的任务
V社回应拒绝上架含 AI 生成内容的游戏:审核政策正在调整中
剧透!蜜小豆@2025世界人工智能大会多个亮点曝光
导演郭帆:人工智能应用可能会影响《流浪地球 3》的创作开发
成功孵化首个大型模型解决方案的重庆人工智能创新中心
厂商陆续公布AI进展 完美世界游戏展示复合应用AI in GamePlay
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
曝光HarmonyOS 4的重要新能力:全面升级AI大模型,小艺实现全面进化
【首发】首款“消化内镜手术机器人”进入临床尾声,ROBO医疗获数千万元A轮融资
微软必应聊天现已在Chrome和Safari浏览器上可用,但仍有许多限制存在
元宇宙迈入2.0时代,它和生成式人工智能有何关联吗?
无需标注数据,「3D理解」进入多模态预训练时代!ULIP系列全面开源,刷新SOTA
Unity 推出面向开发者的 AI 软件市场 AI Hub,股价飙涨 15%
这款在《自然通讯》发表的机器人,为变形金刚来到现实创造可能性
XREAL发布新款硬件XREAL Beam投屏盒子:可悬停AR空间屏
烟台大学学生首次在全国大学生无人机航拍竞赛中获奖
干货满满,2025昆山元宇宙国际装备展等你来打卡!
长宁这家企业在世界人工智能大会上荣获“蓝鼎奖”
大脚攀爬者车主福利!无人机、运动相机大奖等你来挑战
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
微软为 AI 初学者推出免费网课:为期 12 周,共 24 节课
人工智能正在弥合认知和表达之间的鸿沟
扎克伯格吐槽苹果Vision Pro:社交落后Meta太多,无法建设元宇宙
优化J*a与MySQL合作:分享批处理操作的技巧
Xreal AR 眼镜用投屏盒子 Beam 发布:分体式设计,到手 699 元
世界上第一个完全由人工智能驱动的图像编辑器!
泗洪:畅通城市“血管” ,管下机器人来帮忙
AI和ML推动联网设备的增长
阿里达摩院向公众免费开放100项AI专利许可
创新全场景清洁方案!海尔商用机器人首发上市
科技有狠活|时光修复师 :用AI让昨日重现
特斯拉机器人面世 未来将大幅提振磁材需求,引领人工智能时代
田渊栋新作:打开1层Transformer黑盒,注意力机制没那么神秘
首届全国体育人工智能大会在首都体育学院召开
原小米 9 号员工李明打造全球首款 AI 安卓桌面机器人
【|直播|预告】人工智能高峰论坛将于7月2日13:30准时开播!
沐曦首款AI推理GPU亮相:INT8算力达160TOPS!
鸿蒙生态带来了哪些新的流量可能性,包括AI、服务分发和原生智能等方面?
首部国内AI辅助动画片《魔游纪:人工智能辅助篇》预告发布
2025-11-26

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
