近日,深度学习领域知名研究者、lightning ai 的首席人工智能教育者 sebastian raschka 在 cvpr 2025 上发表了主题演讲「scaling pytorch model training with minimal code changes」。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

为了能与更多人分享研究成果,Sebastian Raschka 将演讲整理成一篇文章。文章探讨了如何在最小代码更改的情况下扩展 PyTorch 模型训练,并表明重点是利用混合精度(mixed-precision)方法和多 GPU 训练模式,而不是低级机器优化。
文章使用视觉 Transformer(ViT)作为基础模型,ViT 模型在一个基本数据集上从头开始,经过约 60 分钟的训练,在测试集上取得了 62% 的准确率。
GitHub 地址:https://github.com/rasbt/cvpr2025
以下是文章原文:
在接下来的部分中,Sebastian 将探讨如何在不进行大量代码重构的情况下改善训练时间和准确率。
想要注意的是,模型和数据集的详细信息并不是这里的主要关注点(它们只是为了尽可能简单,以便读者可以在自己的机器上复现,而不需要下载和安装太多的依赖)。所有在这里分享的示例都可以在 GitHub 找到,读者可以探索和重用完整的代码。
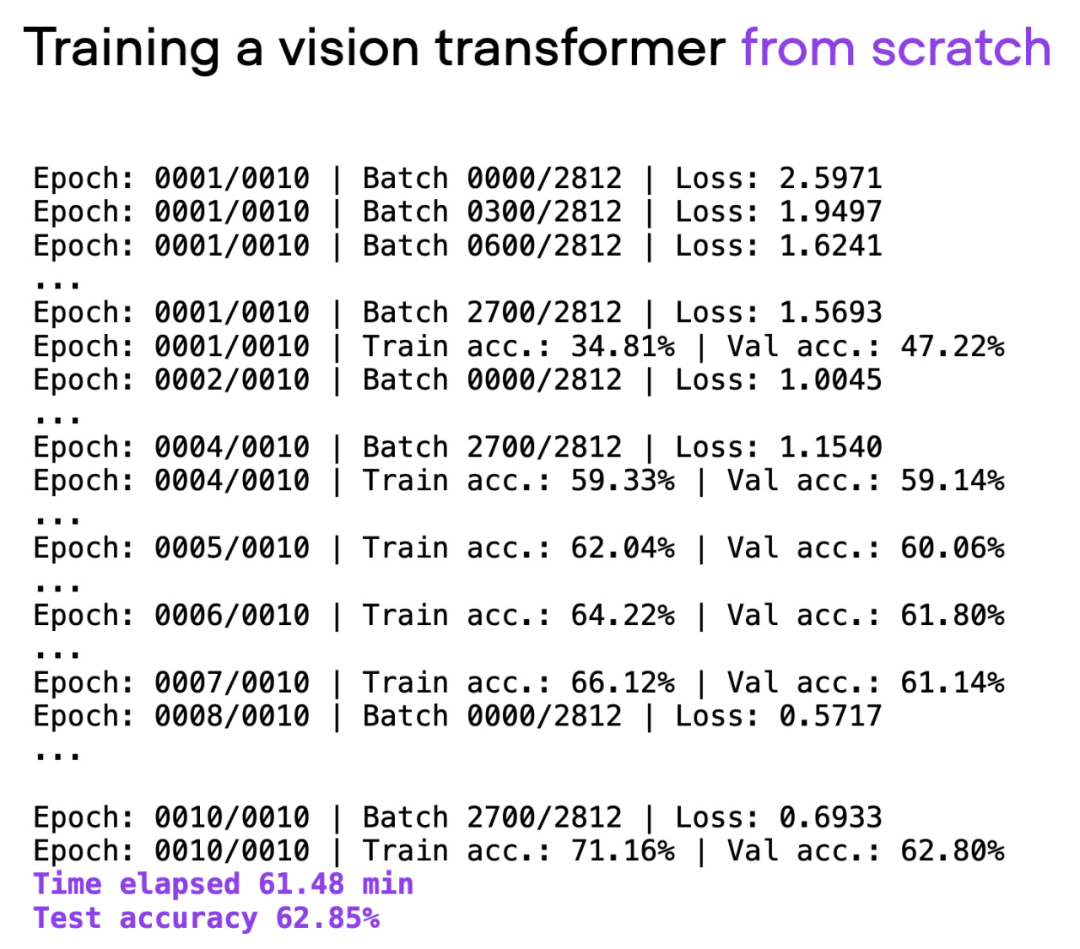
脚本 00_pytorch-vit-random-init.py 的输出。
现如今,从头开始训练文本或图像的深度学习模型通常是低效的。我们通常会利用预训练模型,并对模型进行微调,以节省时间和计算资源,同时获得更好的建模效果。
如果考虑上面使用的相同 ViT 架构,在另一个数据集(ImageNet)上进行预训练,并对其进行微调,就可以在更短的时间内实现更好的预测性能:20 分钟(3 个训练 epoch)内达到 95% 的测试准确率。
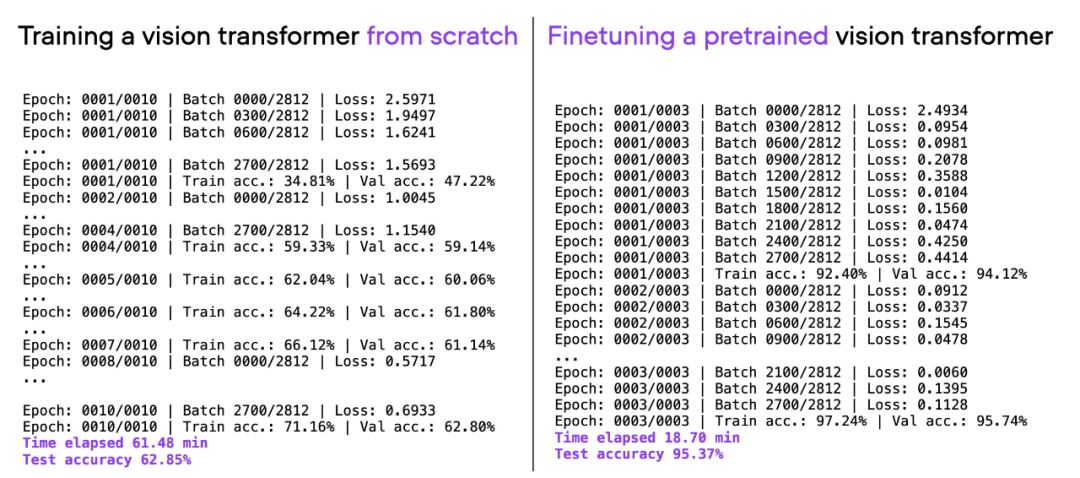
00_pytorch-vit-random-init.py 和 01_pytorch-vit.py 的对比。
我们可以看到,相对于从零开始训练,微调可以大大提升模型性能。下面的柱状图总结了这一点。
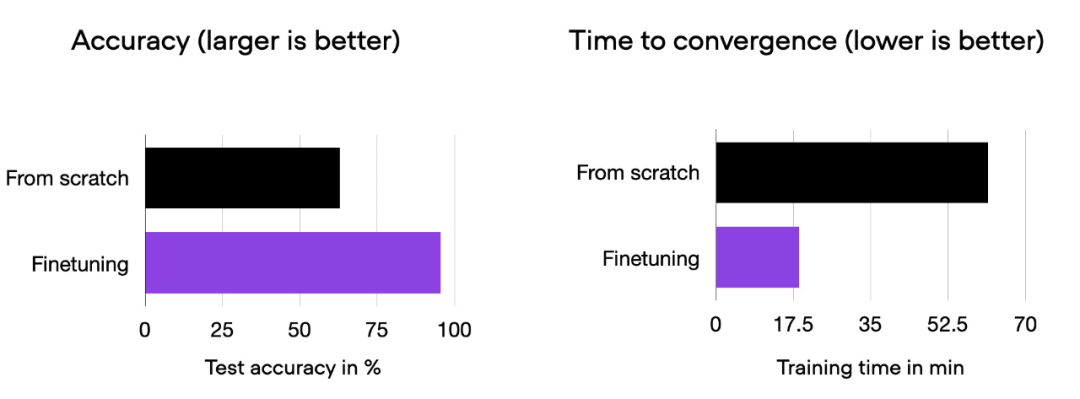
00_pytorch-vit-random-init.py 和 01_pytorch-vit.py 的对比柱状图。
当然,模型效果可能因数据集或任务的不同而有所差异。但对于许多文本和图像任务来说,从一个在通用公共数据集上预训练的模型开始是值得的。
接下来的部分将探索各种技巧,以加快训练时间,同时又不牺牲预测准确性。
在 PyTorch 中以最小代码更改来高效扩展训练的一种方法是使用开源 Fabric 库,它可以看作是 PyTorch 的一个轻量级包装库 / 接口。通过 pip 安装。
pip install lightning
下面探索的所有技术也可以在纯 PyTorch 中实现。Fabric 的目标是使这一过程更加便利。
在探索「加速代码的高级技术」之前 ,先介绍一下将 Fabric 集成到 PyTorch 代码中需要进行的小改动。一旦完成这些改动,只需要改变一行代码,就可以轻松地使用高级 PyTorch 功能。
,先介绍一下将 Fabric 集成到 PyTorch 代码中需要进行的小改动。一旦完成这些改动,只需要改变一行代码,就可以轻松地使用高级 PyTorch 功能。
PyTorch 代码和修改后使用 Fabric 的代码之间的区别是微小的,只涉及到一些细微的修改,如下面的代码所示:
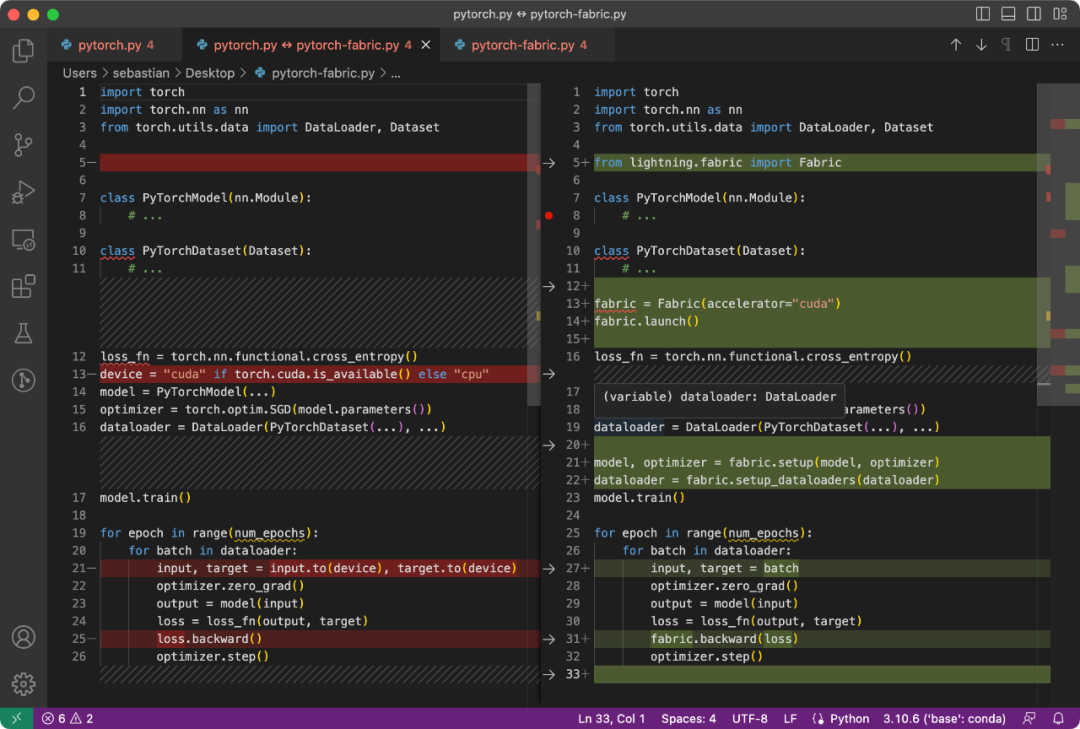
普通 PyTorch 代码(左)和使用 Fabric 的 PyTorch 代码
总结一下上图,就可以得到普通的 PyTorch 代码转换为 PyTorch+Fabric 的三个步骤:

这些微小的改动提供了一种利用 PyTorch 高级特性的途径,而无需对现有代码进行进一步重构。
深入探讨下面的「高级特性」之前,要确保模型的训练运行时间、预测性能与之前相同。
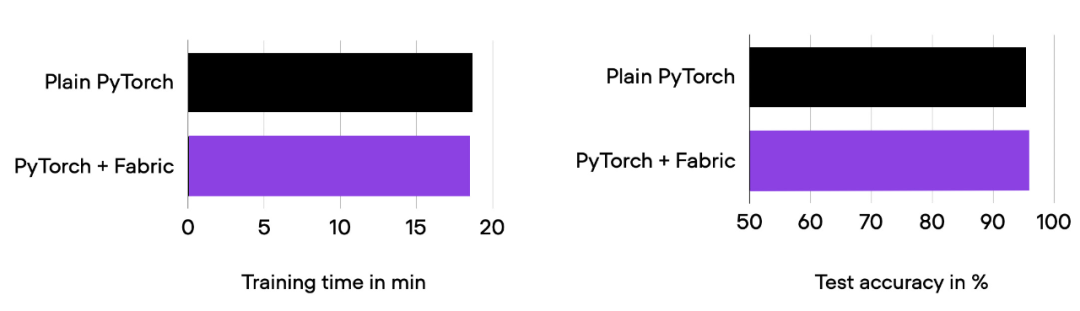
01_pytorch-vit.py 和 03_fabric-vit.py 的比较结果。
正如前面柱状图中所看到的,训练运行时间、准确率与之前完全相同,正如预期的那样。其中,任何波动都可以归因于随机性。
在前面的部分中,我们使用 Fabric 修改了 PyTorch 代码。为什么要费这么大的劲呢?接下来将尝试高级技术,比如混合精度和分布式训练,只需更改一行代码,把下面的代码
fabric = Fabric(accelerator="cuda")
改为
fabric = Fabric(accelerator="cuda", precisinotallow="bf16-mixed")
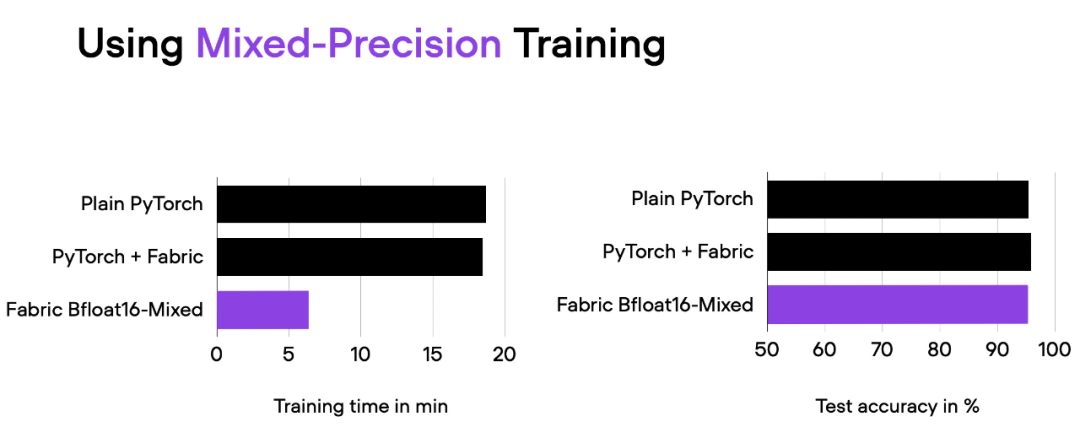
04_fabric-vit-mixed-precision.py 脚本的比较结果。脚本地址:https://github.com/rasbt/cvpr2025/blob/main/04_fabric-vit-mixed-precision.py
通过混合精度训练,我们将训练时间从 18 分钟左右缩短到 6 分钟,同时保持相同的预测性能。这种训练时间的缩短只需在实例化 Fabric 对象时添加参数「precisinotallow="bf16-mixed"」即可实现。
 网易人工智能
网易人工智能
网易数帆多媒体智能生产力平台
 233
查看详情
233
查看详情

混合精度训练实质上使用了 16 位和 32 位精度,以确保不会损失准确性。16 位表示中的计算梯度比 32 位格式快得多,并且还节省了大量内存。这种策略在内存或计算受限的情况下非常有益。
之所以称为「混合」而不是「低」精度训练,是因为不是将所有参数和操作转换为 16 位浮点数。相反,在训练过程中 32 位和 16 位操作之间切换,因此称为「混合」精度。
如下图所示,混合精度训练涉及步骤如下:
这种方法在保持神经网络准确性和稳定性的同时,实现了高效的训练。
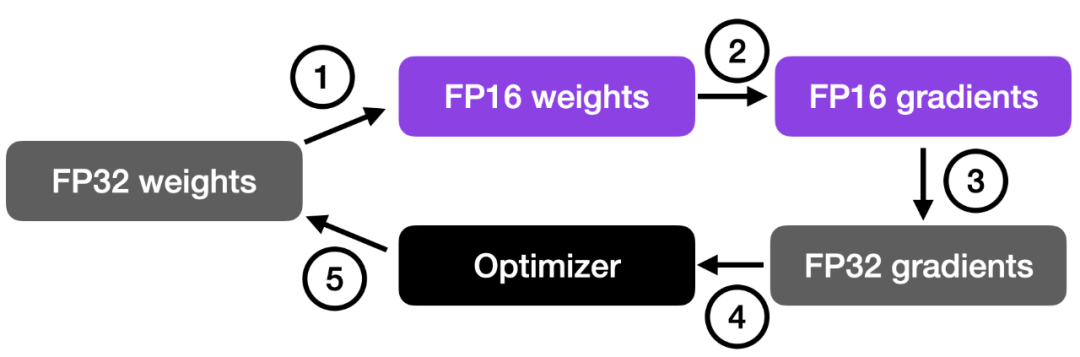
更详细的步骤如下:
步骤 4 中的乘积用于更新原始的 FP32 神经网络权重。学习率有助于控制优化过程的收敛性,对于实现良好的性能非常重要。
前面谈到了「float 16-bit」精度训练。需要注意的是,在之前的代码中,指定了 precisinotallow="bf16-mixed",而不是 precisinotallow="16-mixed"。这两个都是有效的选项。
在这里,"bf16-mixed" 中的「bf16」表示 Brain Floating Point(bfloat16)。谷歌开发了这种格式,用于机器学习和深度学习应用,尤其是在张量处理单元(TPU)中。Bfloat16 相比传统的 float16 格式扩展了动态范围,但牺牲了一定的精度。
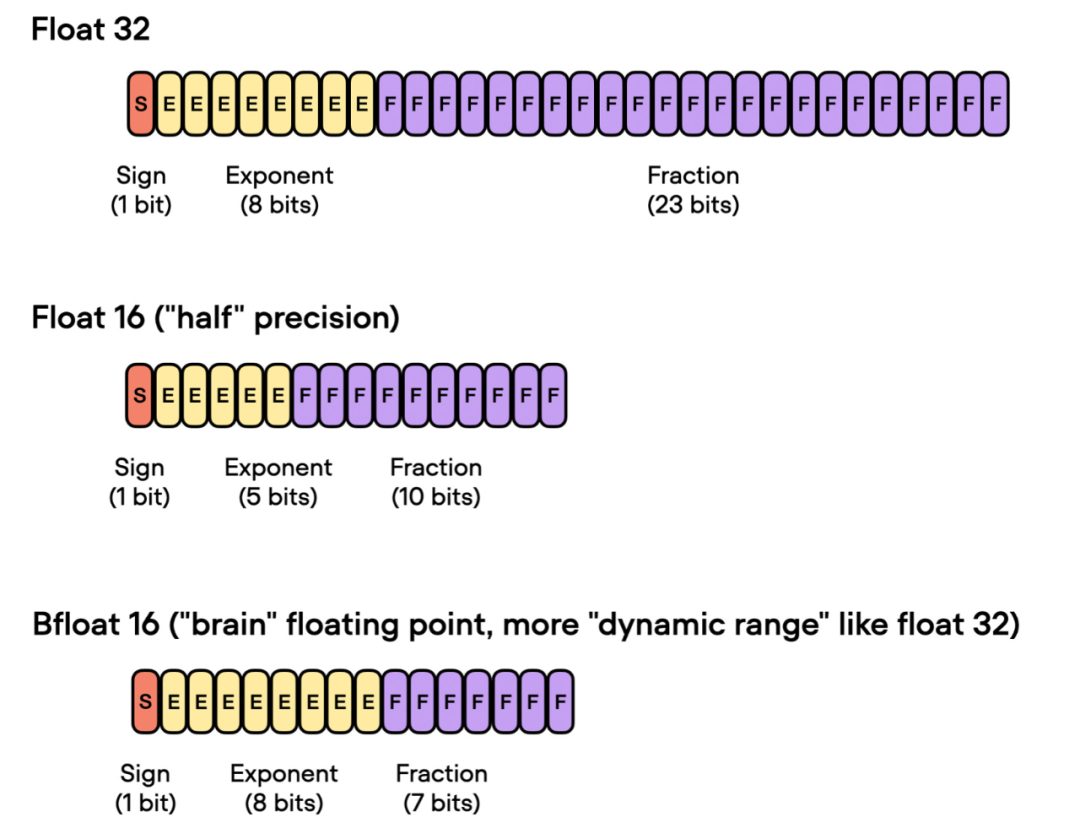
扩展的动态范围使得 bfloat16 能够表示非常大和非常小的数字,使其更适用于深度学习应用中可能遇到的数值范围。然而,较低的精度可能会影响某些计算的准确性,或在某些情况下导致舍入误差。但在大多数深度学习应用中,这种降低的精度对建模性能的影响很小。
虽然 bfloat16 最初是为 TPU 开发的,但从 NVIDIA Ampere 架构的 A100 Tensor Core GPU 开始,已经有几种 NVIDIA GPU 开始支持 bfloat16。
我们可以使用下面的代码检查 GPU 是否支持 bfloat16:
>>> torch.cuda.is_bf16_supported()True
如果你的 GPU 不支持 bfloat16,可以将 precisinotallow="bf16-mixed" 更改为 precisinotallow="16-mixed"。
接下来要尝试修改多 GPU 训练。如果我们有多个 GPU 可供使用,这会带来好处,因为它可以让我们的模型训练速度更快。
这里介绍一种更先进的技术 — 完全分片数据并行(Fully Sharded Data Parallelism (FSDP)),它同时利用了数据并行性和张量并行性。

在 Fabric 中,我们可以通过下面的方式利用 FSDP 添加设备数量和多 GPU 训练策略:
fabric = Fabric(accelerator="cuda", precisinotallow="bf16-mixed",devices=4, strategy="FSDP"# new!)
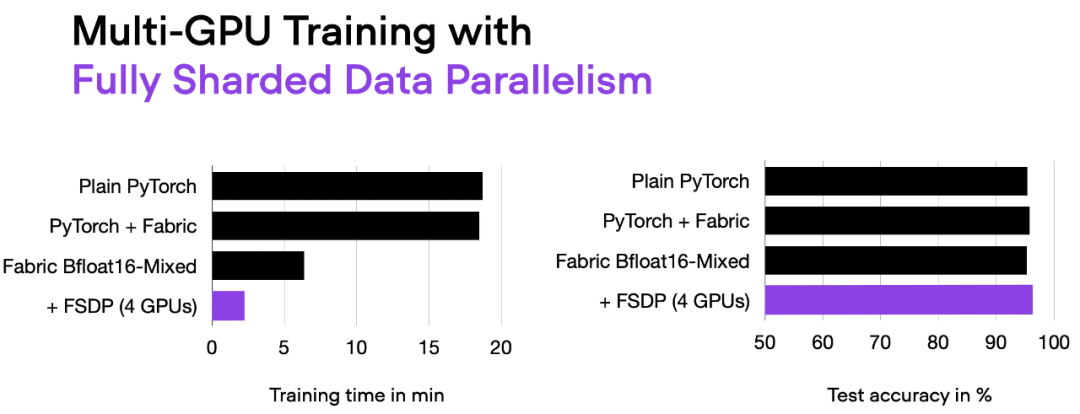
06_fabric-vit-mixed-fsdp.py 脚本的输出。
现在使用 4 个 GPU,我们的代码运行时间大约为 2 分钟,是之前仅使用混合精度训练时的近 3 倍。
在数据并行中,小批量数据被分割,并且每个 GPU 上都有模型的副本。这个过程通过多个 GPU 的并行工作来加速模型的训练速度。
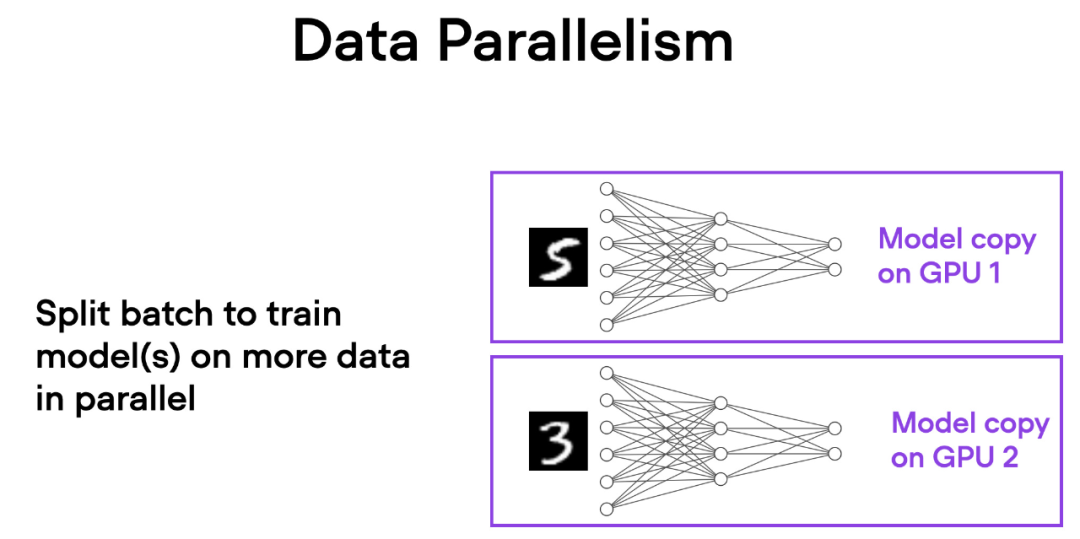
如下简要概述了数据并行的工作原理:
每个 GPU 都在并行地处理不同的数据子集,通过梯度的平均化和参数的更新,整个模型的训练过程得以加速。
这种方法的主要优势是速度。由于每个 GPU 同时处理不同的小批量数据,模型可以在更短的时间内处理更多的数据。这可以显著减少训练模型所需的时间,特别是在处理大型数据集时。
然而,数据并行也有一些限制。最重要的是,每个 GPU 必须具有完整的模型和参数副本。这限制了可以训练的模型大小,因为模型必须适应单个 GPU 的内存。这对于现代的 ViTs 或 LLMs 来说这是不可行的。
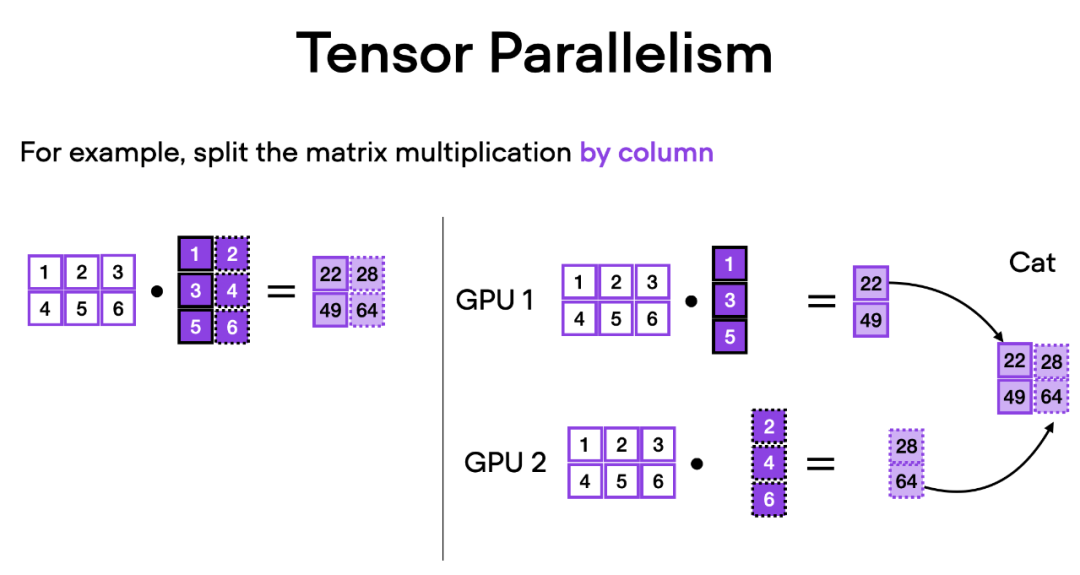
与数据并行不同,张量并行将模型本身划分到多个 GPU 上。并且在数据并行中,每个 GPU 都需要适 应整个模型,这在训练较大的模型时可能成为一个限制。而张量并行允许训练那些对单个 GPU 而言可能过大的模型,通过将模型分解并分布到多个设备上进行训练。
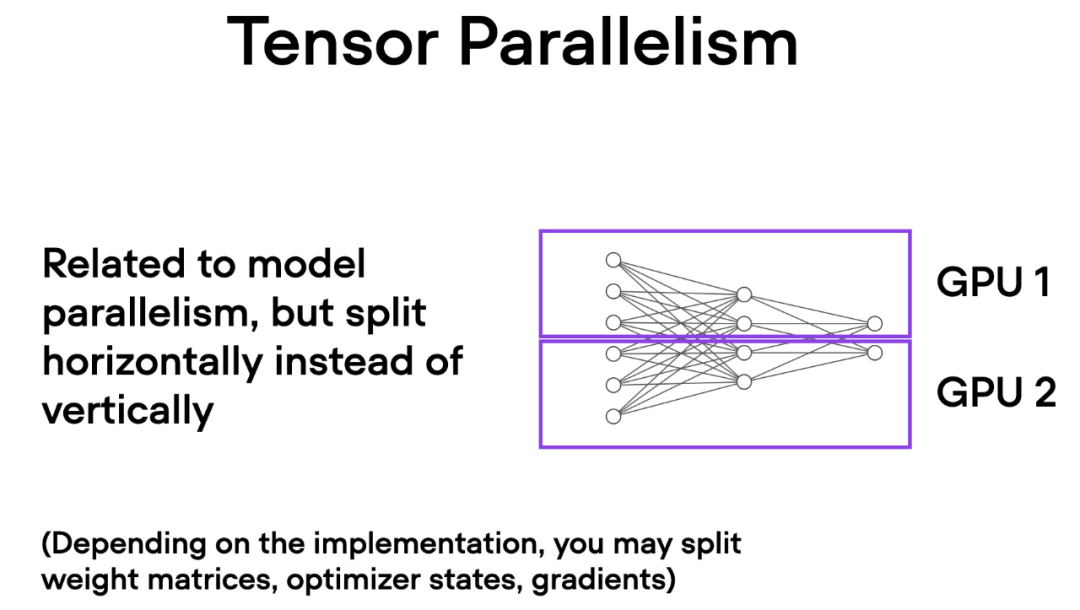
张量并行是如何工作的呢?想象一下矩阵乘法,有两种方式可以进行分布计算 —— 按行或按列。为了简单起见,考虑按列进行分布计算。例如,我们可以将一个大型矩阵乘法操作分解为多个独立的计算,每个计算可以在不同的 GPU 上进行,如下图所示。然后将结果连接起来以获取结果,这有效地分摊了计算负载。
以上就是改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键的详细内容,更多请关注其它相关文章!
# 所示
# 龙里县网站建设
# 玉溪seo如何
# 西区网站建设公司
# 中甸网站推广
# app推广和网站推广
# seo优化及推广快照
# 上犹网站建设推广
# 建德seo网络营销
# 山东数据网站推广哪个好
# 方山信息化网站推广靠谱吗
# 模型
# 中国科学院
# 而不是
# 的是
# 重构
# 开源
# 转换为
# 较低
# 网易
# 多个
# 训练
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
阿里大文娱CTO郑勇:生成式AI将引发内容行业巨变,*制作机会挑战并存
小艺将具备大模型能力,鸿蒙4加速AI普及之路
大疆 DJI Mini 4 Pro 无人机曝光:流线设计,有望迎来功能性提升
磐镭发布全新 GeForce RTX 4080 ARMOUR 显卡,售价为 9499 元
聚焦人工智能大模型、AIGC 徐汇十余场重磅论坛等你来
国宝级文物“铜兽驮跪坐人顶尊铜像”完成模拟拼接,腾讯AI立功
自然语言生成在智能家居设备中的应用
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
科普:什么是AI大模型
谷歌计划在上海举办开发者大会,重点关注机器学习和生成式AI领域
时间、空间可控的视频生成走进现实,阿里大模型新作VideoComposer火了
微软 Copilot 团队主管呼吁用户与 AI 交流时应使用恰当的礼貌用语
超级智能到底是什么?
2025WRC世界机器人大赛锦标赛(烟台)收官!斯坦星球勇夺VEX赛项冠亚军!
鹅厂机器狗抢起真狗「饭碗」!会撒欢儿做游戏,遛人也贼6
谷歌新安卓机器人logo曝光:头更大了
AI大模型紫东太初已被注册商标 中科院已注册紫东太初大模型商标
软银、淡马锡、沙特阿美突击入股,“协作机器人第一股”节卡股份:强敌环伺,持续失血是常态
人工智能正在弥合认知和表达之间的鸿沟
13 个提高生产力的 AI 工具
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
AI 助手 Copilot 上线,微软 Win11 Dev 预览版 Build 23493 发布
一公司推出喷火机器狗,可喷出 9 米长火焰
人手一部「*」!视频版Midjourney免费可用,一句话秒生酷炫大片惊呆网友
可按用户语气自动回复消息,Zoom 推出基于生成式 AI 的新功能
AI框架生态峰会本周开幕 华为昇腾“朋友圈”再聚首 全球首个全模态大模型将登场
首个算网生态体!中国移动元宇宙产业联盟正式成立
世界周刊丨AI“棱镜”?
应对算力挑战,亚马逊云科技发力AI基础设施建设
生成式人工智能如何改变云安全的游戏规则
郭帆:AI发展日新月异,或是弯道超车好莱坞的最好机会
贫穷让我预训练
Moka AI产品后观察:HR SaaS迈进AGI时代
读创正式上线“读创AI聊”功能
深剖Apple Vision Pro中暗藏的“AI”
ChatGPT设计出的第一个机器人来了!【附人工智能行业预测】
日入400万,第一批AI骗子已上岗
马斯克预测:特斯拉全自动驾驶将在今年实现 对AI深度变化感到担忧
研究发现AI聊天机器人ChatGPT不会讲笑话,只会重复25个老梗
助力人工智能产业高质量发展 龙岗区算法训练基地正式启用
首部国内AI辅助动画片《魔游纪:人工智能辅助篇》预告发布
7条线路感受智慧美好生活,“2025 世界人工智能大会民营企业社会开放日”主题活动启动
能走、能飞、能游泳,科学家打造全能 M4 机器人
原小米 9 号员工李明打造全球首款 AI 安卓桌面机器人
12页线性代数笔记登GitHub热榜,还获得了Gilbert Strang大神亲笔题词
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
“痴迷”元宇宙,魔珐科技想做什么?
如何利用物联网技术提高企业生产线智能化水平,提升生产效率
中国气象局预测:到 2030 年,中国人工智能气象应用将达到国际领先水平
IBM CEO克里希纳:人工智能潜在创新无法被监管
2023-08-14

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
